



Clawmotia, an edje MythTV remote control.
Sources hot off the presses: clawmotia-0.0.1. You'll also notice the diablo binary for clawmotia on there so you don't need a scratchbox to get going. I put the clawmotia.edj up too so you don't even need to compile that if you don't wanna.
Planet maemo: category "feed:db85272b5cc4c48c874836930690af4e"

I noticed that there are many packages which turn a maemo device into a remote control. Unfortunately, the MythTV ones I saw either didn't install or were not what I was looking for. Thus clawmotia was born yesterday.
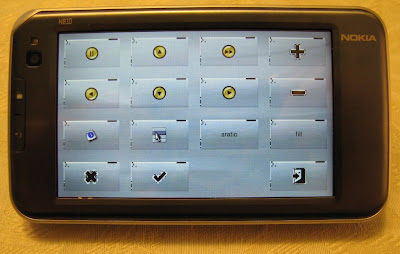
I'm using edje for the interface and qedje to actually create the UI. The program logic uses Qt to talk to a MythTV server and send the commands to it. This relies on knowing there your server is, and what client you want to control which are both passed in as environment variables. Really simple stuff, but it works well.
You'll need the Web interface on the MythTV server machine too. The upshot is that you only need a wifi connection and you can control any MythTV client you want. No bluetooth or IR dongles needed.
As you can see, there are some nasty graphical artifacts on the buttons which I'm not sure if its the evas engine or something to do with qedje. The black parts on the buttons are not there on the desktop.
As it uses edje, you can create different themes and layouts, compile the edje on your desktop machine and just scp it to the device to change the layout and button functionality. Including cute little slide in and out panels for the more rarely used controls. Hopefully I can convince somebody with more artistic ability than me to do just that. Source will be released in the next few days.

I'm using edje for the interface and qedje to actually create the UI. The program logic uses Qt to talk to a MythTV server and send the commands to it. This relies on knowing there your server is, and what client you want to control which are both passed in as environment variables. Really simple stuff, but it works well.
You'll need the Web interface on the MythTV server machine too. The upshot is that you only need a wifi connection and you can control any MythTV client you want. No bluetooth or IR dongles needed.
As you can see, there are some nasty graphical artifacts on the buttons which I'm not sure if its the evas engine or something to do with qedje. The black parts on the buttons are not there on the desktop.
As it uses edje, you can create different themes and layouts, compile the edje on your desktop machine and just scp it to the device to change the layout and button functionality. Including cute little slide in and out panels for the more rarely used controls. Hopefully I can convince somebody with more artistic ability than me to do just that. Source will be released in the next few days.
I've started work on a memory mapped soprano RDF backend. Given that mobile devices use flash for their permanent storage, an RDF backend designed using primary storage algorithms should work well on maemo.
While the SPARQL implementation is "far from complete", it can already evaluate some common queries very very quickly. I have some triple matching and the ability to have multiple regex filter statements. Other filters and more complete SPARQL lanugage support should follow in time, as time permits... patches accepted etc and so on.
For those interested, see soprano-boostmmapbackend on my main sf.net page.
While the SPARQL implementation is "far from complete", it can already evaluate some common queries very very quickly. I have some triple matching and the ability to have multiple regex filter statements. Other filters and more complete SPARQL lanugage support should follow in time, as time permits... patches accepted etc and so on.
For those interested, see soprano-boostmmapbackend on my main sf.net page.
In the early days there was prelink as part of maemo. It disappeared in the n810 distribution ranges. I noticed that there is no armel deb in debian for prelink, but there were murmurs of folks hacking it to work. Push finally came to shove, and as I like C++ many of my apps on maemo have quite a few symbols that need to be resolved before the app can run.
The long story short, prelink_0.0.20090311 is up at my repo. Use at your own risk, if your device breaks you get to keep both pieces etc etc.
Initial benchmarking: for an app that uses a few libraries, is C++, and has quite a few symbols that the dynamic linker has to attend to. For a complete run before it was 5.2 seconds on a warm start, with prelink of the binary it is 2.5 seconds. Considering that in that 2.5 the app itself has to completely run, there was a huge amount of time spent, err wasted, in the dynamic linker.
Of course, if I can get hidden symbols to work too then that 2.5 might drop back to 1.5-2 seconds. But for hidden symbols you have to either wrap things in pragmas or declare each function and class as exposed or not, so for a large library its quite intrusive. But the prelink is a huge gain for no code changes, so far at least. YMMV.
It's a touch ironic that Nokia recommends using prelink for embedded devices. But that is for qtopia... maybe for the next distro prelink will reappear in the default installation.
The long story short, prelink_0.0.20090311 is up at my repo. Use at your own risk, if your device breaks you get to keep both pieces etc etc.
Initial benchmarking: for an app that uses a few libraries, is C++, and has quite a few symbols that the dynamic linker has to attend to. For a complete run before it was 5.2 seconds on a warm start, with prelink of the binary it is 2.5 seconds. Considering that in that 2.5 the app itself has to completely run, there was a huge amount of time spent, err wasted, in the dynamic linker.
Of course, if I can get hidden symbols to work too then that 2.5 might drop back to 1.5-2 seconds. But for hidden symbols you have to either wrap things in pragmas or declare each function and class as exposed or not, so for a large library its quite intrusive. But the prelink is a huge gain for no code changes, so far at least. YMMV.
It's a touch ironic that Nokia recommends using prelink for embedded devices. But that is for qtopia... maybe for the next distro prelink will reappear in the default installation.
After noticing that gphoto is not packaged for maemo I did a bit of digging, seeing sad news from those who tried getting it going. But I thought I'd try with 2.4.6 to see if things are better now.

For those who want to tinker, see my packages. The library came across OK but gphoto itself uses a newer debhelper, so I just plucked the binary itself into the repo. If you want to use this with libferris, then expand the additional libraries into /usr/local/lib/ferris/plugins/context on the device.
I found that once USB mode was set to host, I could see the camera with gphoto but as reported in the past, there were frequent crashes. This is really unfortunate as all the blocks where in place for the command I was chasing:
Most of the time using gphoto locks everything and about 5-10 seconds later the device restarts. I might have to hunt for a newer kernel for diablo... or wait until I have gphoto support on an n9 (nn?), a P+S wifi camera, and a decent data plan...

For those who want to tinker, see my packages. The library came across OK but gphoto itself uses a newer debhelper, so I just plucked the binary itself into the repo. If you want to use this with libferris, then expand the additional libraries into /usr/local/lib/ferris/plugins/context on the device.
I found that once USB mode was set to host, I could see the camera with gphoto but as reported in the past, there were frequent crashes. This is really unfortunate as all the blocks where in place for the command I was chasing:
# ferriscp -av \
gphoto://Canon.../DCIM/102CANON/IMG_2442.JPG \
flickr://me/upload
Most of the time using gphoto locks everything and about 5-10 seconds later the device restarts. I might have to hunt for a newer kernel for diablo... or wait until I have gphoto support on an n9 (nn?), a P+S wifi camera, and a decent data plan...
New debs allowing you to copy to flickr, 23hq, vimeo, youtube etc from the n810 are available. The next step is closer integration, tapping into the "send to" menu to let you send any image file to these places. Hey, its just a filesystem now ;)
One interesting possibility is using the n810 to shuttle images from a digital camera to the net. This gets around the vendor lock-in that might be present on your camera because the n810 just grabs the images from the cam and then shuttles them onward to wherever.
I also updated libferris to allow you to authenticate from the console, just the ticket to let you set things up over ssh with your desktop browser.
OK, for maemo, check the repository and you'll want ferris, libferris, and libferrisui at least. Version 1.3.6.
If you get into dependency trouble, see the build order to get an idea of the tree. Sorry its a bit hard to get on the device, hopefully stuff will move into extras in time.
Anyone who has used desktop flickr tools, you'll know about the whole authenticate before you buy thing. The below commands setup 23hq and copy an image over to it.
Hopefully things will become easier in the future: installation, setup etc. Of course, streaming from the webcam to youtube will rock, but baby steps as they say.
One interesting possibility is using the n810 to shuttle images from a digital camera to the net. This gets around the vendor lock-in that might be present on your camera because the n810 just grabs the images from the cam and then shuttles them onward to wherever.
I also updated libferris to allow you to authenticate from the console, just the ticket to let you set things up over ssh with your desktop browser.
OK, for maemo, check the repository and you'll want ferris, libferris, and libferrisui at least. Version 1.3.6.
If you get into dependency trouble, see the build order to get an idea of the tree. Sorry its a bit hard to get on the device, hopefully stuff will move into extras in time.
Anyone who has used desktop flickr tools, you'll know about the whole authenticate before you buy thing. The below commands setup 23hq and copy an image over to it.
$ ferris-capplet-auth --list-auth-sites
...
flickr
23hq
...
$ ferris-capplet-auth --auth-with-site 23hq
...
Grant Auth following URL...
http://www.23hq.com/services/auth/?api_key=...
Then press return to continue...
<Open above link in browser, grant auth, hit return>
Done...
$ ferriscp -av 26082009071.jpg 23hq://me/upload
Hopefully things will become easier in the future: installation, setup etc. Of course, streaming from the webcam to youtube will rock, but baby steps as they say.
It always stuck me as a little odd that you have specific applications to upload to flickr, another little app with a cute interface for throwing video files at webserviceY etc. I should also mention that all of this is coming to the maemo build shortly... what better place to unlock web services than a tablet or phone, neh?
If you are in Europe and want to hear about libferris and other cool storage stuff (register &) drop by the
NLUUG Spring Conference on Storage on the 7th of May.
I will of course have a maemo unit running libferris there as well as a laptop. Carrying a server with ferris is a bit too much though :) I'm brewing up the slides now with XQuery, KML, and SQLite goodness. Probably not the first three terms you think of when the words Virtual Filesystem are muttered.
NLUUG Spring Conference on Storage on the 7th of May.
I will of course have a maemo unit running libferris there as well as a laptop. Carrying a server with ferris is a bit too much though :) I'm brewing up the slides now with XQuery, KML, and SQLite goodness. Probably not the first three terms you think of when the words Virtual Filesystem are muttered.
So, long story short, the place I was hosting my maemo repository was on a host at the university I did my PhD at. The server has been suffering unpredictable hardware issues so I have now moved the repository. There is a new subdomain fuuko.libferris.com where I'll be putting up some libferris related stuff, including packages.
In particular, the new libferris maemo repository is now up.
Also note that I have binary rpm files for Fedora 10 in both 32 and 64 bit at OBS.
In particular, the new libferris maemo repository is now up.
Also note that I have binary rpm files for Fedora 10 in both 32 and 64 bit at OBS.
Most of the index engine implementations in libferris will detect when you try to add the same file again, and when it hasn't changed in a meaningful way will just skip reindexing it. This makes it really easy to just use the below command to update the index for a specific filesystem.
$ find /Data | feaindexadd --filelist-stdin
The trick comes in when /Data is an NFS share with 400,000 files on it that you are accessing from a Nokia n810. Or when /Data is a file server that you are indexing from your laptop over wifi or another sluggish, higher latency network.
feaindexadd can be told to directly traverse one or more directories and so you don't have to use find in the above command. But separating out the find from the indexing has a really big advantage: you can update indexes of extremely large, but infrequently changing NFS shares very quickly -- Even over slow networks.
The trick is to do the filesystem traversal on the server side, and just pump the URLs that are interesting to the client machine:
ssh lowaccess@server 'find /Data -mtime -10' \
| feaindexadd --filelist-stdin
Of course, this relies on /Data being the same filesystem on both the server and the client. Otherwise you're in for some fun with sed or awk to mangle the paths to be what the client expects.
And the 10 in the above means that you'll have to run the command from cron within 10 days to maintain a complete index. You might find that doing a "time find /Data" on the client and server has significant performance differences, particularly if the filesystem has many files.
You can always store and search the index from the file server, but for disconnected searching, you really need to have the index itself stored on the maemo device.
$ find /Data | feaindexadd --filelist-stdin
The trick comes in when /Data is an NFS share with 400,000 files on it that you are accessing from a Nokia n810. Or when /Data is a file server that you are indexing from your laptop over wifi or another sluggish, higher latency network.
feaindexadd can be told to directly traverse one or more directories and so you don't have to use find in the above command. But separating out the find from the indexing has a really big advantage: you can update indexes of extremely large, but infrequently changing NFS shares very quickly -- Even over slow networks.
The trick is to do the filesystem traversal on the server side, and just pump the URLs that are interesting to the client machine:
ssh lowaccess@server 'find /Data -mtime -10' \
| feaindexadd --filelist-stdin
Of course, this relies on /Data being the same filesystem on both the server and the client. Otherwise you're in for some fun with sed or awk to mangle the paths to be what the client expects.
And the 10 in the above means that you'll have to run the command from cron within 10 days to maintain a complete index. You might find that doing a "time find /Data" on the client and server has significant performance differences, particularly if the filesystem has many files.
You can always store and search the index from the file server, but for disconnected searching, you really need to have the index itself stored on the maemo device.
In a previous post I had a video showing one of the libferris inverted file metadata index plugins on maemo. Unfortunately that implementation was designed for a desktop machine, meaning for many many more files, slow disk head seeks, blazingly fast CPU(s).
Searching for audio files on an NFS share from maemo from Ben Martin on Vimeo.
The n810 only has one memory slot. With an 8gb card in there you might fit 1,000 ogg files onto your storage. That was quite boaring, so I instead indexed an NFS share that is over 10x larger ;) I'm using one of the libferris inverted file backends for the index, which is more targeted at the desktop machine assumptions of having a faster CPU and expensive disk head seeks. Needless to say, I'm hacking on a custom index implementation for maemo which will be more oriented at a slower CPU with much much less expensive disk seeks for flash based storage.
Note that the time after I run ferris-music-search to when the first message appears on the console "Using index..." is fairly much all wasted in dynamic linking. A major slowdown that I've yet to sweep away for running apps on maemo.
The artist and title info is taken from the ID3 tags in the audio files. Indexing time is roughly 3 to 10 milliseconds per file when performed on the desktop. The inverted file index format is portable from desktop to maemo device. I plan to make the new explicit maemo format portable too, so you can make indexes on powerful machines and rsync them over to the maemo device. Assuming you are indexing stuff that is stored on your file server, not the maemo device.
During the typing for the first search on title, possible completions are shown by taking your input as a substring of the title you seek. This is more effective if you keep it in mind because you can choose just a few keys in a substring of the title. All searches are performed using regex matching on strings, which is much slower than direct equality because of the huge complications it introduces for indexing. But it is interesting, even with modestly 10x the number of files you can cram onto an n810, using nasty slow regex searching, the performance is acceptable for much of the time. There are a few cases that I'll improve, particularly regex searching on whole URLs.
Notice that the name and URL are shown as columns, so you can easily "group by" when you click on the appropriate header. I need to also include the artist, title etc ID3 fields into the results,. Oh, and have the ability to click on a few files and see the whole ID3 and metadata of those files "side-by-side" so you do not have to try to read it from the results list.
So now when I see a CD in the shops, I wont have to wonder how many of those Mozart tracks I have already, I can know for sure :-p