| GObject Reference Manual |
|---|
C APIs are defined by a set of functions and global variables which are usually exported from a binary. C functions have an arbitrary number of arguments and one return value. Each function is thus uniquely identified by the function name and the set of C types which describe the function arguments and return value. The global variables exported by the API are similarly identified by their name and their type.
A C API is thus merely defined by a set of names to which a set of types are associated. If you know the function calling convention and the mapping of the C types to the machine types used by the platform you are on, you can resolve the name of each function to find where the code associated to this function is located in memory, and then construct a valid argument list for the function. Finally, all you have to do is trigger a call to the target C function with the argument list.
For the sake of discussion, here is a sample C function and the associated 32 bit x86 assembly code generated by GCC on my Linux box:
static void function_foo (int foo)
{}
int main (int argc, char *argv[])
{
function_foo (10);
return 0;
}
push $0xa
call 0x80482f4 <function_foo>
The assembly code shown above is pretty straightforward: the first instruction pushes
the hexadecimal value 0xa (decimal value 10) as a 32-bit integer on the stack and calls
function_foo. As you can see, C function calls are implemented by
gcc by native function calls (this is probably the fastest implementation possible).
Now, let's say we want to call the C function function_foo from
a Python program. To do this, the Python interpreter needs to:
Find where the function is located. This probably means finding the binary generated by the C compiler which exports this function.
Load the code of the function in executable memory.
Convert the Python parameters to C-compatible parameters before calling the function.
Call the function with the right calling convention.
Convert the return values of the C function to Python-compatible variables to return them to the Python code.
The process described above is pretty complex and there are a lot of ways to make it entirely automatic and transparent to C and Python programmers:
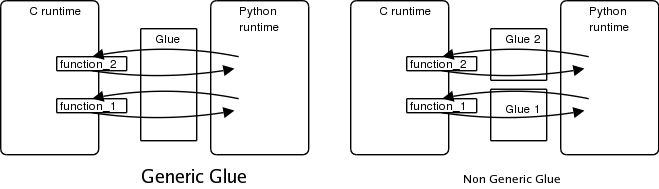
The first solution is to write by hand a lot of glue code, once for each function exported or imported, which does the Python-to-C parameter conversion and the C-to-Python return value conversion. This glue code is then linked with the interpreter which allows Python programs to call Python functions which delegate work to C functions.
Another, nicer solution is to automatically generate the glue code, once for each function exported or imported, with a special compiler which reads the original function signature.
The solution used by GLib is to use the GType library which holds at runtime a description of all the objects manipulated by the programmer. This so-called dynamic type [1] library is then used by special generic glue code to automatically convert function parameters and function calling conventions between different runtime domains.
The greatest advantage of the solution implemented by GType is that the glue code sitting at the runtime domain boundaries is written once: the figure below states this more clearly.
Currently, there exist at least Python and Perl generic glue code which makes it possible to use
C objects written with GType directly in Python or Perl, with a minimum amount of work: there
is no need to generate huge amounts of glue code either automatically or by hand.
Although that goal was arguably laudable, its pursuit has had a major influence on the whole GType/GObject library. C programmers are likely to be puzzled at the complexity of the features exposed in the following chapters if they forget that the GType/GObject library was not only designed to offer OO-like features to C programmers but also transparent cross-language interoperability.
[1] There are numerous different implementations of dynamic type systems: all C++ compilers have one, Java and .NET have one too. A dynamic type system allows you to get information about every instantiated object at runtime. It can be implemented by a process-specific database: every new object created registers the characteristics of its associated type in the type system. It can also be implemented by introspection interfaces. The common point between all these different type systems and implementations is that they all allow you to query for object metadata at runtime.